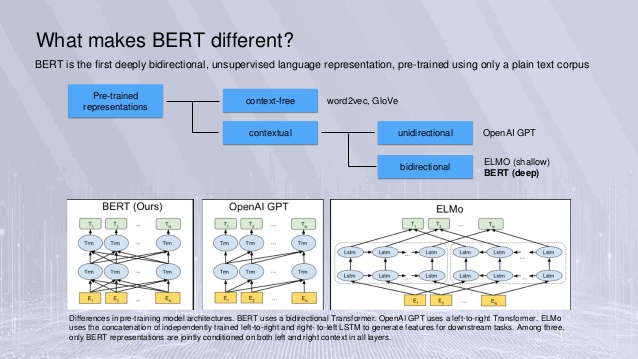
1. BERT의 개요
- 트랜스포머를 이용하여 구현되었으며, 위키피디아(25억 단어)와 BooksCorpus(8억 단어)와 같은 레이블이 없는 텍스트 데이터로 사전 훈련 및 파인 튜닝(Fine-tuning)된 언어 모델
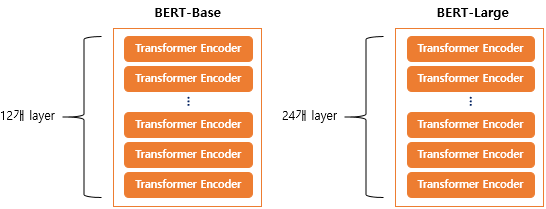
2. BERT의 크기
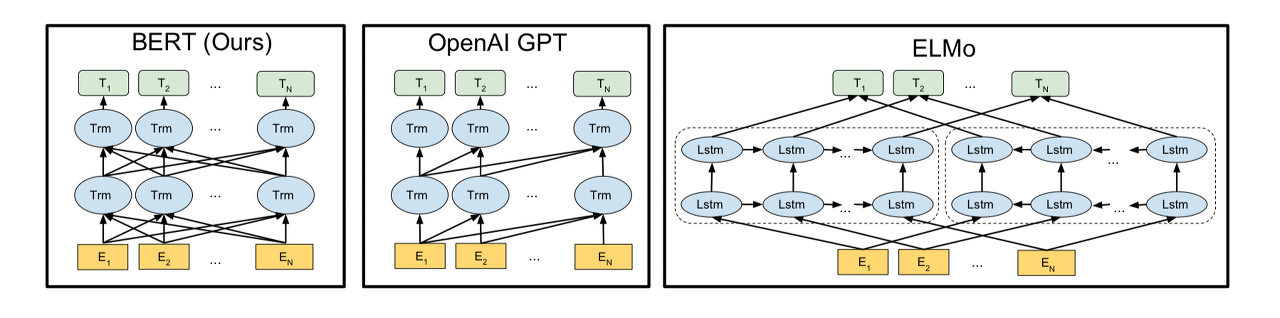
- 기본 구조는 트랜스포머의 인코더를 쌓아올린 구조
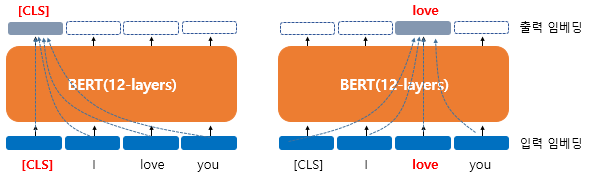
3. BERT의 문맥을 반영한 임베딩(Contextual Embedding)
- 문맥을 반영한 임베딩(Contextual Embedding)을 사용
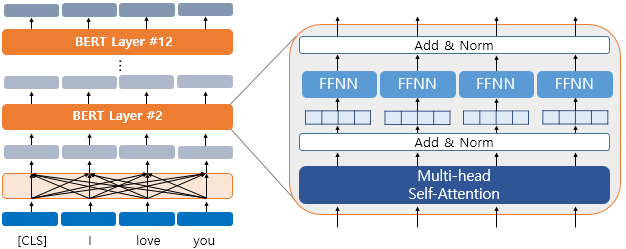
- 하나의 단어가 모든 단어를 참고하는 연산은 BERT의 12개의 층에서 전부 이루어짐
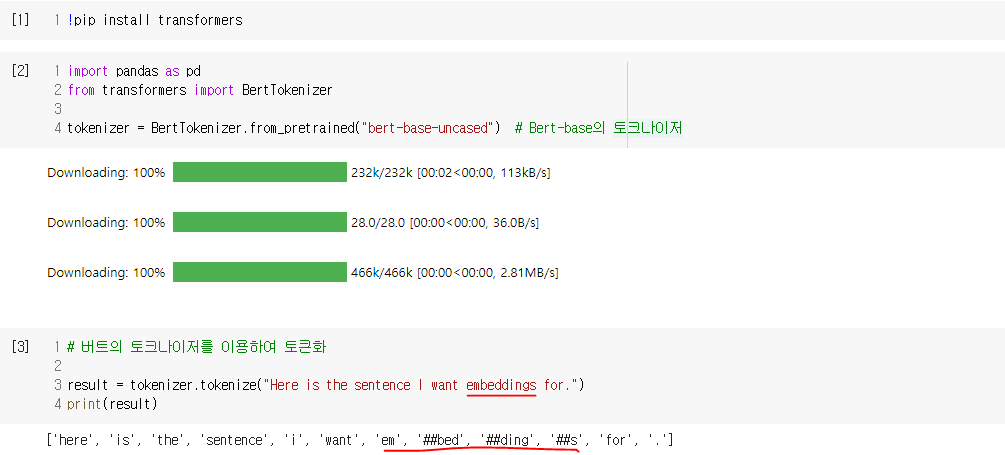
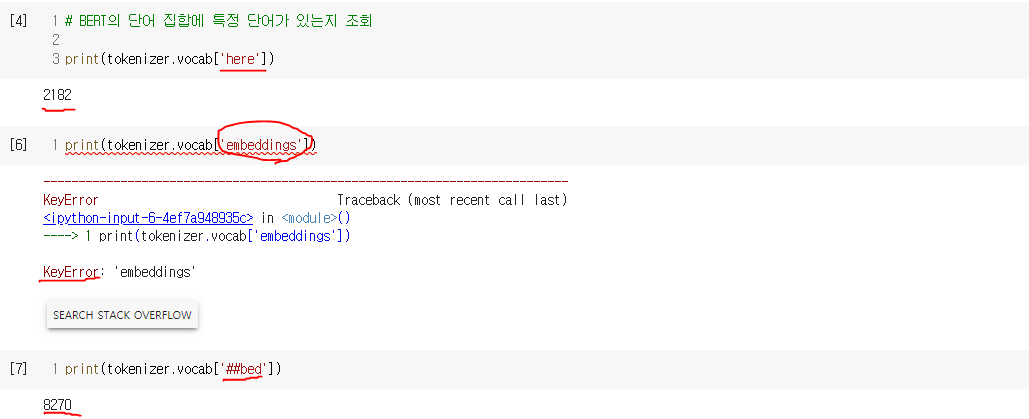
4. BERT의 서브워드 토크나이저 : WordPiece
- 단어보다 더 작은 단위로 쪼개는 서브워드 토크나이저를 사용(WordPiece 토크나이저)
- 자주 등장하지 않는 단어의 경우 더 작은 단위인 서브워드로 분리되어 서브워드들이 단어 집합에 추가

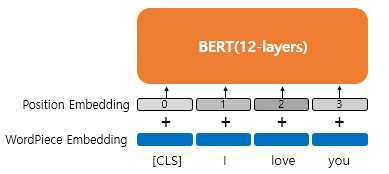
5. 포지션 임베딩(Position Embedding)
- 위치 정보를 위한 임베딩 층(Embedding layer)을 하나 더 사용하여 학습을 통해서 얻은 위치 정보를 표현
6. BERT의 사전 훈련(Pre-training)
- 두 가지 방식
- 마스크드 언어 모델(Masked Language Model, MLM)
- 다음 문장 예측(Next Sentence Prediction, NSP)
1) 마스크드 언어 모델(Masked Language Model, MLM)
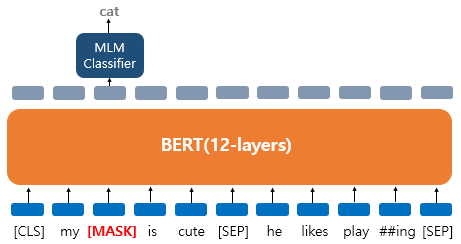
- 입력 텍스트의 15%의 단어를 랜덤으로 마스킹(Masking)하여 이 가려진 단어들을(Masked words) 예측하도록 함
- 80%의 단어들은 [MASK]로 변경한다.
Ex) The man went to the store → The man went to the [MASK] - 10%의 단어들은 랜덤으로 단어가 변경된다.
Ex) The man went to the store → The man went to the dog - 10%의 단어들은 동일하게 둔다.
Ex) The man went to the store → The man went to the store
2) 다음 문장 예측(Next Sentence Prediction, NSP)
- 두 개의 문장(두 종류의 텍스트, 두 개의 문서 등의 의미도 포함)을 준 후에 이 문장이 이어지는 문장인지 아닌지를 맞추는 방식으로 훈련함

- 이어지는 문장의 경우
Sentence A : The man went to the store.
Sentence B : He bought a gallon of milk.
Label = IsNextSentence - 이어지는 문장이 아닌 경우 경우
Sentence A : The man went to the store.
Sentence B : dogs are so cute.
Label = NotNextSentence
7. 세그먼트 임베딩(Segment Embedding)
- 문장 구분을 위해서 세그먼트 임베딩이라는 또 다른 임베딩 층(Embedding layer)을 사용
*** 결론적으로 BERT는 총 3개의 임베딩 층이 사용됨
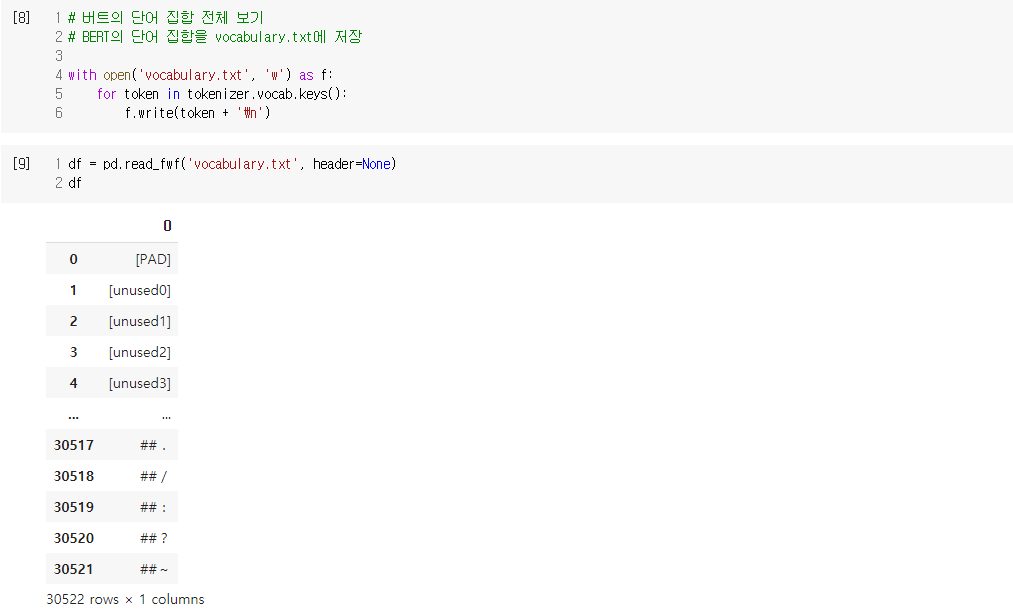
- WordPiece Embedding : 실질적인 입력이 되는 워드 임베딩. 임베딩 벡터의 종류는 단어 집합의 크기로 30,522개.
- Position Embedding : 위치 정보를 학습하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 길이인 512개.
- Segment Embedding : 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개.
8. BERT를 파인 튜닝(Fine-tuning) : 적용 유형
- BERT에 우리가 풀고자 하는 태스크의 데이터를 추가로 학습 시켜서 테스트하는 단계
1) 하나의 텍스트에 대한 텍스트 분류 유형(Single Text Classification)
- 영화 리뷰 감성 분류, 로이터 뉴스 분류 등과 같이 입력된 문서에 대해서 분류를 하는 유형
2) 하나의 텍스트에 대한 태깅 작업(Tagging)
- 문장의 각 단어에 품사를 태깅하는 품사 태깅 작업과 개체를 태깅하는 개체명 인식 작업 등의 유형
3) 텍스트의 쌍에 대한 분류 또는 회귀 문제(Text Pair Classification or Regression)
- 자연어 추론(Natural language inference) 등의 유형
4) 질의 응답(Question Answering)
- 텍스트의 쌍을 입력으로 받는 또 다른 태스크 유형 등
10. 어텐션 마스크(Attention Mask)
- BERT가 어텐션 연산을 할 때, 불필요하게 패딩 토큰에 대해서 어텐션을 하지 않도록 실제 단어와 패딩 토큰을 구분할 수 있도록 알려주는 입력(0, 1)
- 출처 : [딥러닝을이용한 자연어 처리 입문] 1802 버트(Bidirectional Encoder Representations from Transformers, BERT)



