■ Apache Pig란?
- Hadoop을 구성하는 하부 프로젝트 중 하나로 MapReduce에 특화된 개발 툴
- 대용량 데이터 셋을 좀 더 고차원 적으로 처리하는 플렛폼
- 대규모 병렬 처리에 대응할 수 있는 구조를 가지고 있으며 이 특징 때문에 대규모 데이터 셋을 처리 할 수 있다.
- Pig의 언어 계층은 Pig Latin이라는 텍스트 기반의 언어로 되어 있다.
■ Pig Latin?
- 쉬운 프로그래밍: 복잡하고 긴 MapReduce코드를 간편한 언어로 보기 좋은 데이터 흐름을 명시적으로 보여 줄 수 있는 코드 작성을 가능하도록 하면 이해와 유지보수도 용이하다.
- 최적화: 시스템이 코드를 자동으로 최적화 해주므로 사용자는 효율성을 생각하지 않고 프로그래밍 내용에만 집중 할 수 있다.
- 효율성: 사용자 자신이 목적에 맞게 자신이 필요로 하는 함수를 구현할 수 있다.
■ Pig 특징
- 사용자 코드를 Plug-In 하기 쉽다. Java 코드를 이용하여 사용자 정의 함수를 사용 가능하며 yahoo와 오픈소스 개발자들에 의해서 개발된 다수의 Pig 라이브러리가 존재
- 메타 데이터를 반드시 지정하지 않아도 된다. 유사한 데이터 포맷이라면 동일한 Pig 스크립트로 처리가능
- 데이터 모델을 강요하지 않는다. SQL은 테이블과 컬럼명에 의존한 Query Language 이나 Pig Latin은 데이터의 Value Focus
- 데이터 흐름을 중심으로 한 처리 내용을 정의할 수 있다. 데이터 흐름에 대해서 함수를 적용하여 계산할 수 있어 처리 흐름을 쉽게 파악
- 다양한 데이터 타입을 지원한다. 일반적인 배열 이외에 Bag, Tuple등을 지원한다.
■ Pig 단점
- 사용하기 편하지만 성능 문제가 발생할 수 있다.
- Pig와 MapReduce를 적절히 혼합해서 사용할 필요가 있다.
- 특정 작업에 Pig? MapReduce?를 결정하는 것이 중요
** 설명출처: K-ICT 빅데이터센터 "8월 빅데이터 분석인프라 활용 교육 교재"
** 문서:
 8월 빅데이터 분석 인프라 활용 교육_최종.vol1.egg
8월 빅데이터 분석 인프라 활용 교육_최종.vol1.egg'IT 와 Social 이야기' 카테고리의 다른 글
| [ciokorea] 우리회사는 AI. 머신러닝에 준비돼 있을까? - 10가지 체크리스트 - Martin Heller | CIO (0) | 2017.09.01 |
|---|---|
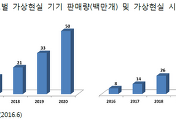
| [digieco] 가상현실 콘텐츠 확보를 통한 국내 미디어 시장 선도 전략 (0) | 2017.08.31 |
| [LX 한국국토정보공사] 4차 산업혁명시대 'LX_Geo고' 탄생 (0) | 2017.08.30 |
| [IITP] 사이버보험을 위한 해외 주요국의 사고데이터 공유 현황 (0) | 2017.08.30 |
| [IITP] 제4차 산업혁명 시대에서 IoT의 발전 방향 - 을지대 강민수 교수 (0) | 2017.08.30 |