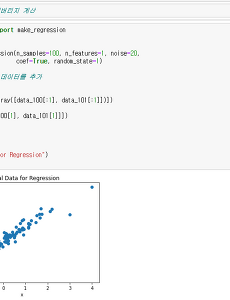
데이터분석17 [데이터 사이언스 스쿨] 5.3 레버지리와 아웃라이어 개별적인 데이터 표본 하나하나가 회귀분석 결과에 미치는 영향력은 레버리지 분석이나 아웃라이어 분석을 통해 알 수 있다. ○ 레버리지(leverage) : 실제 종속변수값이 예측치(predicted target)에 미치는 영향을 나타낸 값 ○ 아웃라이어(outlier) : 모형에서 설명하고 있는 데이터와 동떨어진 값을 가지는 데이터, 즉 잔차가 큰 데이터. 잔차의 크기는 독립 변수의 영향을 받으므로 아웃라이어를 찾으려면 이 영향을 제거한 표준화된 잔차를 계산해야 한다. - 출처 : [데이터 사이언스 스쿨] 5.3 레버지리와 아웃라이어 2021. 5. 10. [데이터 사이언스 스쿨] 5.1 확률론적 선형 회귀모형 probabilistic model ○ 부트스트래핑(bootstrapping) : 회귀분석에 사용한 표본 데이터가 달라질 때 회귀분석의 결과는 어느 정도 영향을 받는지를 알기 위한 방법이다. - 기존의 데이터를 재표본화(re-sampling)하여 여러가지 다양한 표본 데이터 집합을 만드는 방법을 사용한다. 재표본화는 기존의 N개의 데이터에서 다시 N개의 데이터를 선택하되 중복 선택도 가능하게 한다(unordered resampling with replacement). ○ 위 summary는 확률론적 선형 회귀모형을 사용한 것이다. 확률론적 선형 회귀모형을 쓰면 부트스트래핑처럼 많은 계산을 하지 않아도 빠르고 안정적으로 가중치 추정값의 오차를 구할 수 있다. ○ 확률론적 선형 회귀모형에서는 데이터가 확률 변수로부터 생성된 표본이라고 가정한다.. 2021. 5. 10. [데이터 사이언스 스쿨] ml1.1 데이터 분석의 소개 ● 예측(prediction) : 예측이란 숫자, 문서, 이미지, 음성, 영상 등의 여러 가지 입력 데이터를 주면, 데이터 분석의 결과로 다른 데이터를 출력하는 분석 방법이다. - 데이터 분석에서 말하는 예측이라는 용어는 시간상으로 미래의 의미는 포함하지 않는다. 시계열 분석에서는 시간상으로 미래의 데이터를 예측하는 경우가 있는데 이 때는 미래예측(forecasting) 이라는 용어를 사용한다. ● 입력 데이터(input data) : 분석의 기반이 되는 데이터로 보통 알파벳 X로 표기한다. - 독립변수(independent variable), 특징(feature), 설명변수(explanatory variable) 등의 용어로 쓰기도 한다. ● 출력 데이터(output data) : 추정하거나 예측하고자.. 2021. 5. 5. [친절한 AI] 머신러닝, 데이터 준비 방법 - 데이터 제공 사이트, 전처리 방법 ★ 데이터 준비 절차 1. 문제 정의 - 어떤 문제를 해결하고 싶은가? 2. 데이터 수집 ① 공개 데이터 활용 [국내] - AI 팩토리 : http://aifactory.space - 공공데이터포털 : https://www.data.go.kr/datasetsearch - AI허브 : http://www.aihub.or.kr - 데이콘 : https://dacon.io - 보건의료빅데이터개방시스템 : https://opendata.hira.or.kr [국외] - 캐글 : https://www.kaggle.com/datasets - 구글 : https://toolbox.google.com/datasetsearch - 레딧 : https://www.reddit.com/r/datasets/ - U.. 2021. 4. 2. 이전 1 2 3 4 5 다음