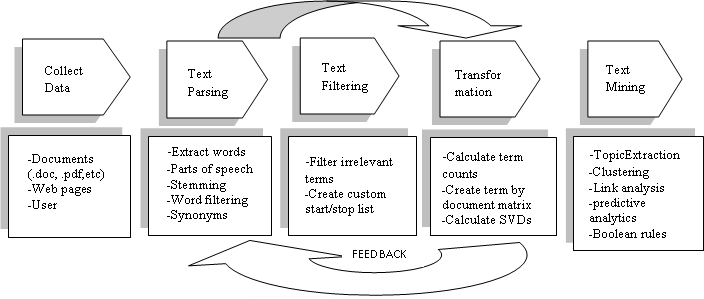
1. 토큰화(Tokenization)
주어진 코퍼스(corpus)에서 토큰(token)이라 불리는 단위로 나누는 작업을 토큰화(tokenization)라고 부릅니다. 토큰의 단위가 상황에 따라 다르지만, 보통 의미있는 단위로 토큰을 정의합니다.
2. 정제(Cleaning)와 정규화(Nomalization)
- 정제(cleaning) : 갖고 있는 코퍼스로부터 노이즈 데이터를 제거한다.
- 정규화(normalization) : 표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만들어준다.
3. 어간 추출(Stemming)과 표제어 추출(Lemmatization)
정규화 기법 중 코퍼스에 있는 단어의 개수를 줄일 수 있는 기법으로 의미는 눈으로 봤을 때는 서로 다른 단어들이지만, 하나의 단어로 일반화시킬 수 있다면 하나의 단어로 일반화시켜서 문서 내의 단어 수를 줄이겠다는 것입니다.
4. 불용어(Stopword)
자주 등장하지만 분석을 하는 것에 있어서는 큰 도움이 되지 않는 단어들을 단어들을 불용어(stopword)라고 하며, 데이터에서 유의미한 단어 토큰만을 선별하기 위해서는 큰 의미가 없는 단어 토큰(불용어)을 제거하는 작업이 필요합니다.
5. 정규 표현식(Regular Expression)
특정한 규칙을 가진 문자열 집합, 즉 유의미한 표현으로 정제하는 것을 말합니다.
6. 정수 인코딩(Integer Encording)
분석이 용이하도록 단어와 맵핑되는 고유한 정수(인덱스)를 부여하는 작업입니다.
7. 패딩(Padding)
병렬 연산을 위해서 여러 문장의 길이를 임의로 동일하게 맞춰주는 작업입니다.
8. 원-핫 인코딩(One-Hot Encoding)
원-핫 인코딩은 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식입니다.
9. 데이터 분리(Splitting Data)
머신 러닝(딥 러닝) 모델에 데이터를 훈련시키기 위해서 데이터를 적절히 분리하는 작업입니다.
10. 한국어 전처리 패키지(Text Preprocessing Tools for Korean Text)
- PyKoSpacing
- Py-Hanspell
- SOYNLP
- Customized KoNLPy



