
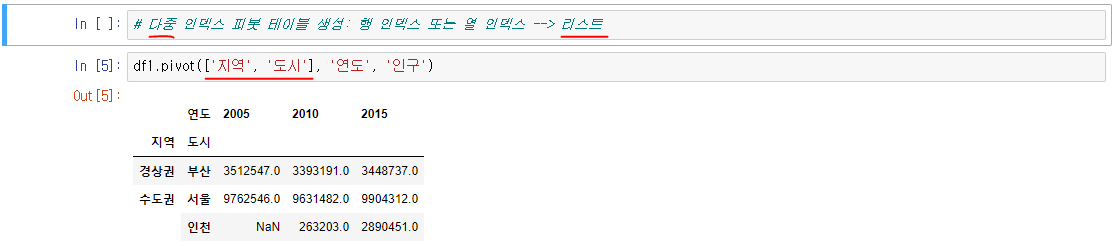
데이터 열 중에서 두 개의 열을 각각 행 인덱스, 열 인덱스로 사용하여 데이터를 조회하여 펼쳐놓은 것을 말한다.




● 그룹분석 (group analysis)
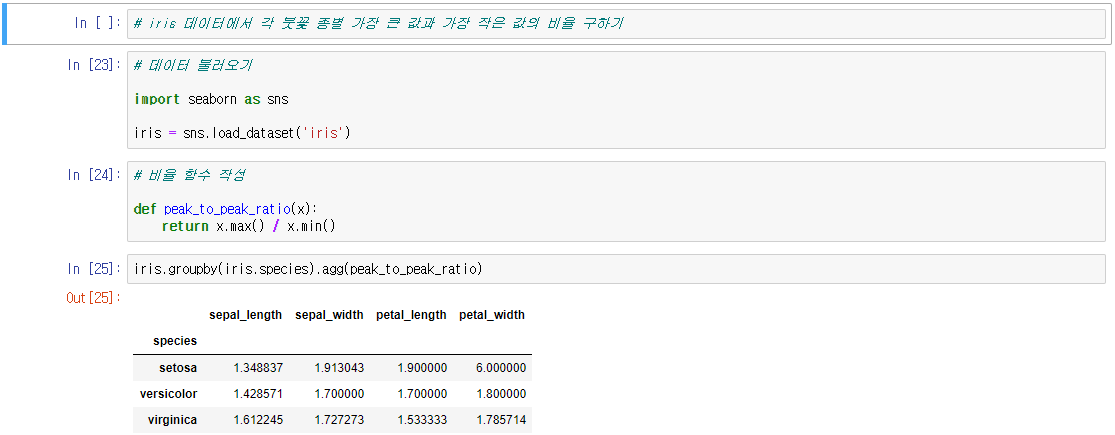
키가 지정하는 조건에 맞는 데이터가 그룹을 이루는 경우, 미리 지정한 연산을 통해 해당 그룹 데이터의 대표값을 계산한다.
- groupby
- 열 또는 열의 리스트
- 행 인덱스
- size, count: 그룹 데이터의 갯수
- mean, median, min, max: 그룹 데이터의 평균, 중앙값, 최소, 최대
- sum, prod, std, var, quantile : 그룹 데이터의 합계, 곱, 표준편차, 분산, 사분위수
- first, last: 그룹 데이터 중 가장 첫번째 데이터와 가장 나중 데이터
- agg, aggregate
- 만약 원하는 그룹연산이 없는 경우 함수를 만들고 이 함수를 agg에 전달한다.
- 또는 여러가지 그룹연산을 동시에 하고 싶은 경우 함수 이름 문자열의 리스트를 전달한다.
- describe
- 하나의 그룹 대표값이 아니라 여러개의 값을 데이터프레임으로 구한다.
- apply
- describe 처럼 하나의 대표값이 아닌 데이터프레임을 출력하지만 원하는 그룹연산이 없는 경우에 사용한다.
- transform
- 그룹에 대한 대표값을 만드는 것이 아니라 그룹별 계산을 통해 데이터 자체를 변형한다.







● pivot_table
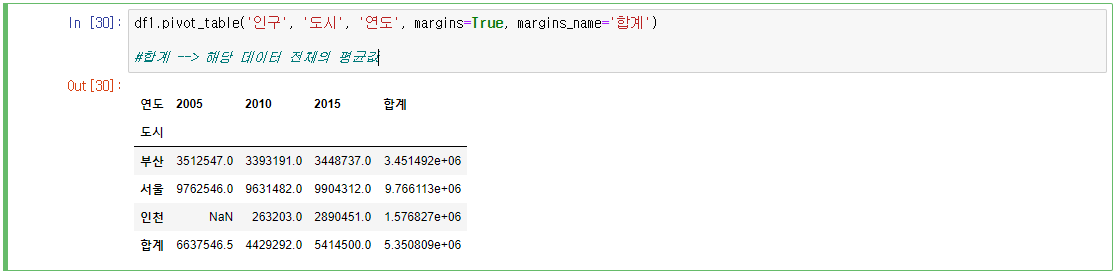
groupby 명령처럼 그룹분석을 하지만 최종적으로는 pivot 명령처럼 피봇테이블을 만든다. 즉 groupby 명령의 결과에 unstack을 자동 적용하여 2차원적인 형태로 변형한다.
- pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, margins_name='All')
- data: 분석할 데이터프레임 (메서드일 때는 필요하지 않음)
- values: 분석할 데이터프레임에서 분석할 열
- index: 행 인덱스로 들어갈 키 열 또는 키 열의 리스트
- columns: 열 인덱스로 들어갈 키 열 또는 키 열의 리스트
- aggfunc: 분석 메서드
- fill_value: NaN 대체 값
- margins: 모든 데이터를 분석한 결과를 오른쪽과 아래에 붙일지 여부
- margins_name: 마진 열(행)의 이름









dss4_7_pivot table and groupby.ipynb
0.09MB
'IT 와 Social 이야기 > Python' 카테고리의 다른 글
| [데이터 사이언스 스쿨] 5.1 시각화 패키지 matplotlib 소개 (0) | 2021.04.28 |
|---|---|
| [데이터 사이언스 스쿨] 4.8 시계열 자료 다루기 (0) | 2021.04.28 |
| [데이터 사이언스 스쿨] 4.6 데이터프레임 합성 (0) | 2021.04.28 |
| [데이터 사이언스 스쿨] 4.5 데이터프레임 인덱스 조작 (0) | 2021.04.28 |
| [데이터 사이언스 스쿨] 4.4 데이터프레임의 데이터 조작 (0) | 2021.04.27 |



