
- 2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델로 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현한 모델
- 이 모델은 RNN을 사용하지 않고, 인코더-디코더 구조를 설계하였음에도 성능도 RNN보다 우수하다는 특징을 갖고 있음
2. 트랜스포머(Transformer)의 주요 하이퍼파라미터
- 아래에서 정의하는 수치값은 트랜스포머를 제안한 논문에서 사용한 수치값으로 하이퍼파라미터는 사용자가 모델 설계시 임의로 변경할 수 있는 값들임
- dmodel = 512
트랜스포머의 인코더와 디코더에서의 정해진 입력과 출력의 크기. 임베딩 벡터의 차원 또한 dmodel이며, 각 인코더와 디코더가 다음 층의 인코더와 디코더로 값을 보낼 때에도 이 차원을 유지. 논문에서는 512.
- num_layers = 6
트랜스포머에서 하나의 인코더와 디코더를 층으로 생각하였을 때, 트랜스포머 모델에서 인코더와 디코더가 총 몇 층으로 구성되었는지를 의미. 논문에서는 인코더와 디코더를 각각 총 6개 쌓음.
- num_heads = 8
트랜스포머에서는 어텐션을 사용할 때, 1번 하는 것 보다 여러 개로 분할해서 병렬로 어텐션을 수행하고 결과값을 다시 하나로 합치는 방식을 택함. 이때 이 병렬의 개수를 의미.
- dff = 2048
트랜스포머 내부에는 피드 포워드 신경망이 존재함. 이때 은닉층의 크기를 의미. 피드 포워드 신경망의 입력층과 출력층의 크기는 dmodel.
3. 트랜스포머(Transformer)
- RNN을 사용하지 않지만 기존의 seq2seq처럼 인코더에서 입력 시퀀스를 입력받고, 디코더에서 출력 시퀀스를 출력하는 인코더-디코더 구조를 유지. 다른 점은 이전 seq2seq 구조에서는 인코더와 디코더에서 각각 하나의 RNN이 t개의 시점(time-step)을 가지는 구조였다면 이번에는 인코더와 디코더라는 단위가 N개로 구성되는 구조

4. 포지셔널 인코딩(Positional Encoding)
- 트랜스포머는 단어 입력을 순차적으로 받는 방식이 아니므로 단어의 위치 정보를 다른 방식으로 알려줄 필요가 있음. 트랜스포머는 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용함, 이를 포지셔널 인코딩(positional encoding)이라고 함
- 트랜스포머는 사인 함수와 코사인 함수의 값(임베딩 벡터 내의 각 차원의 인덱스가 짝수인 경우에는 사인 함수의 값을 사용하고 홀수인 경우에는 코사인 함수의 값을 사용)을 임베딩 벡터에 더해주므로서 단어의 순서 정보를 제공함
- 결국 트랜스포머의 입력은 순서 정보가 고려된 임베딩 벡터


5. 어텐션(Attention)
- 트랜스포머에서 사용되는 세 가지 어텐션

- 인코더의 셀프 어텐션 : Query = Key = Value
- 디코더의 마스크드 셀프 어텐션 : Query = Key = Value
- 디코더의 인코더-디코더 어텐션 : Query : 디코더 벡터, Key = Value : 인코더 벡터
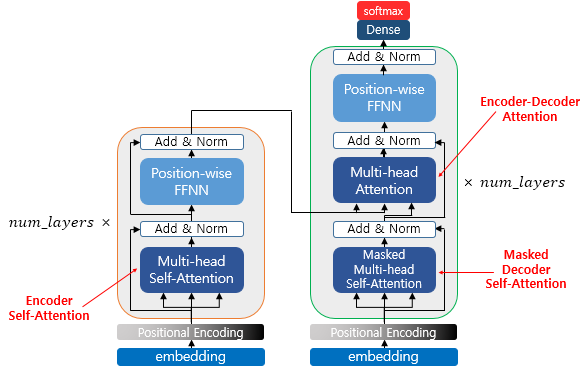
6. 인코더(Encoder)
- 트랜스포머는 하이퍼파라미터인 num_layers 개수의 인코더 층을 쌓음

7. 인코더의 셀프 어텐션
5) 스케일드 닷-프로덕트 어텐션 구현하기





7) 멀티 헤드 어텐션(Multi-head Attention) 구현하기



8) 패딩 마스크(Padding Mask)
- 마스킹이란 어텐션에서 제외하기 위해 값을 가린다는 의미
- 마스킹을 하는 방법은 어텐션 스코어 행렬의 마스킹 위치에 매우 작은 음수값을 넣어주는 것


10. 인코더 구현하기

11. 인코더 쌓기

13. 디코더의 첫번째 서브층 : 셀프 어텐션과 룩-어헤드 마스크

15. 디코더 구현하기

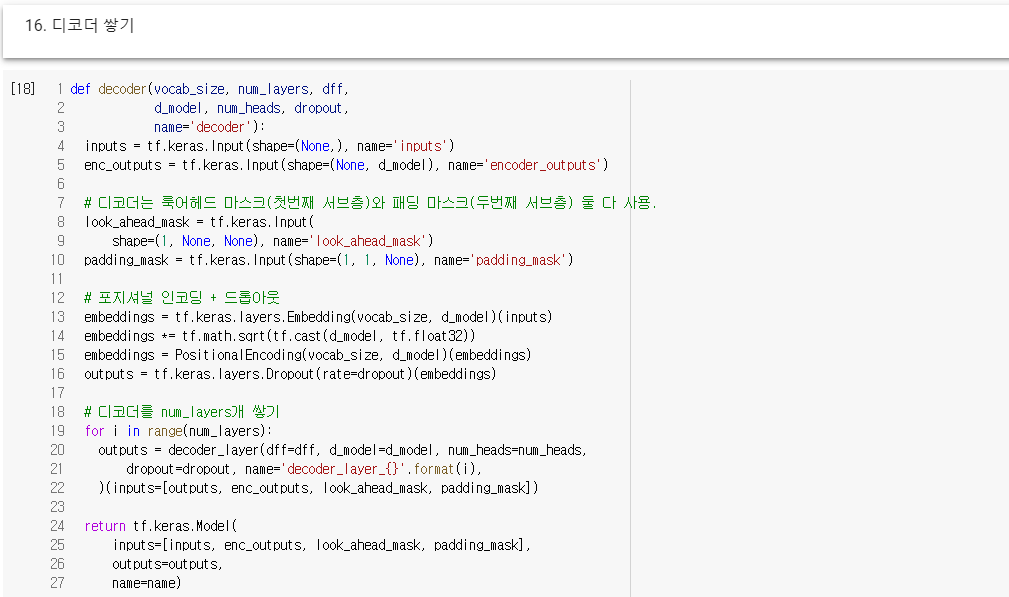
16. 디코더 쌓기
17. 트랜스포머 구현하기

18. 트랜스포머 하이퍼파라미터 정하기

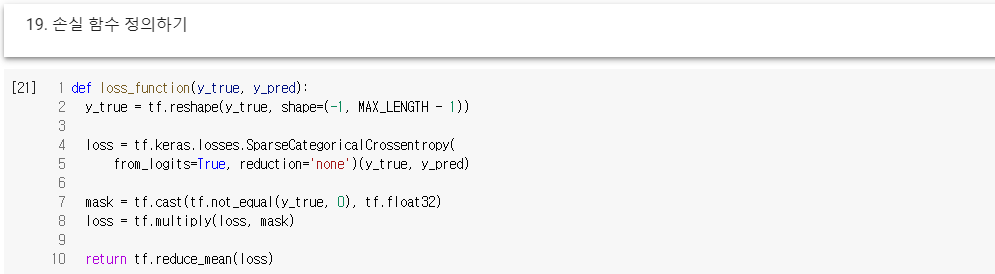
19. 손실 함수 정의하기
20. 학습률





