1. Babi 데이터셋

- 총 20가지의 질문 내용으로 구성
- 시간 순서대로 나열된 텍스트 문장 정보와 그에 대한 질문으로 구성
- 텍스트 정보에 대해 질문을 하고 응답하는 형태
- 다운로드 페이지 : https://research.fb.com/downloads/babi/
2. 메모리 네트워크 구조
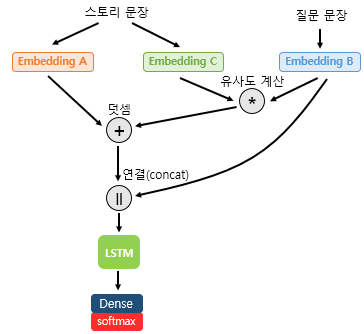
- 예측 과정 : 입력되는 스토리 문장을 Value와 Key, 질문 문장을 Query라고 하면
- Query는 Key와 유사도를 구하고, 소프트맥스 함수를 통해 값을 정규화하여 Value에 더해서 이 유사도값을 반영해 줌(어텐션 메커니즘)
- 이 스토리 문장 표현을 질문 문장을 임베딩한 질문 표현과 연결(concatenate)해줌
- 이 표현을 LSTM과 밀집층(dense layer)의 입력으로 사용하여 정답을 예측
3. Babi 데이터셋 전처리하기

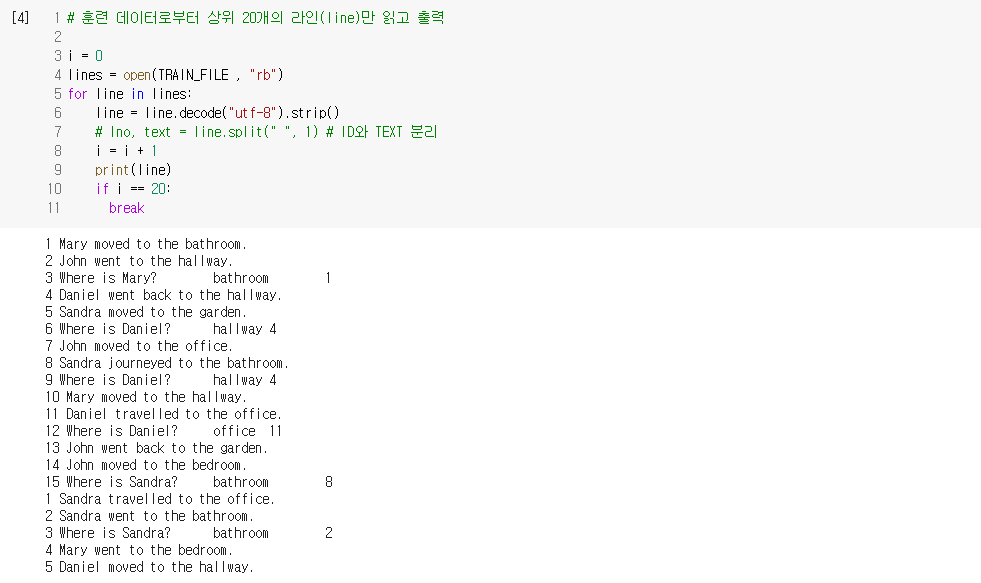
- 숫자 1부터 15까지 한 개의 스토리
- 3번, 6번, 9번, 12번, 15번 라인과 같이 리스트 중에 질문이 나옴
- 질문 옆에는 해당되는 정답과 정답이 나온 리스트 행 번호
- 숫자 1이 다시 나오면 이제부터는 다시 별개의 스토리가 시작됨을 의미





4. 메모리 네트워크로 QA 태스크 풀기







nlp_2001_qa_system_with_memory_network.ipynb
0.02MB
- [딥러닝을이용한 자연어 처리 입문] 2001 메모리 네트워크(Memory Network, MemN)를 이용한 QA
'IT 와 Social 이야기 > NLP 자연어처리' 카테고리의 다른 글
| 자연어 처리 강의 영상 추천 : [고현웅] Large-scale LM에 대한 얕고 넓은 지식들 (part 1) (0) | 2021.06.17 |
|---|---|
| 자연어 처리 강의 영상 추천 : [Ready-To-Use Tech] 자연어 처리 (0) | 2021.06.16 |
| [딥러닝을이용한 자연어 처리 입문] 1902 문장 임베딩 기반 텍스트 랭크(TextRank Based on Sentence Embedding) (0) | 2021.06.05 |
| [딥러닝을이용한 자연어 처리 입문] 1901 어텐션을 이용한 텍스트 요약(Text Summarization with Attention mechanism) (0) | 2021.06.04 |
| [딥러닝을이용한 자연어 처리 입문] 1803 코랩(Colab)에서 TPU 사용하기 (0) | 2021.06.04 |



