- 논문 : https://arxiv.org/abs/2004.12943
Audio-Visual Instance Discrimination with Cross-Modal Agreement
We present a self-supervised learning approach to learn audio-visual representations from video and audio. Our method uses contrastive learning for cross-modal discrimination of video from audio and vice-versa. We show that optimizing for cross-modal discr
arxiv.org
○ 논문 설명
- 이 논문은 UC San Diego와 Facebook 소속의 저자들이 공동 작성한 것으로 CVPR 2021에서 베스트 페이퍼 후보에 오르기도 했습니다.
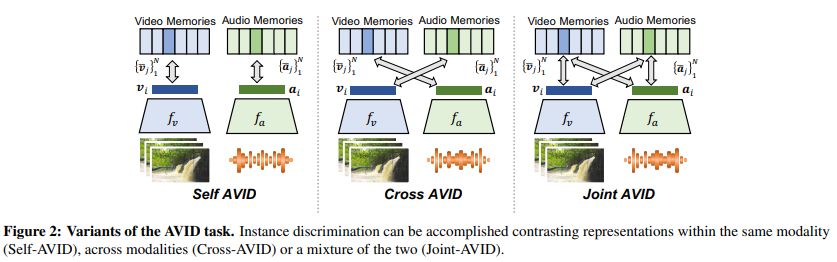
- 논문에서는 비디오에서 얻을 수 있는 visual feature와 audio feature를 교차 활용하는 강력한 pre-train 방법으로 Cross-AVID를 제안하고,
- 이를 통해 action recognition, sound classification과 같은 각 modality별 downstream task 성능이 SOTA 수준으로 향상되는 것을 확인합니다.
- 동시에, Cross-AVID가 가질 수 있는 한계를 지적하고 이를 극복하기 위한 Cross-Modal Agreement (CMA)라는 추가 방법론까지 제안합니다.
- 중간 규모에서 대규모 스케일의 학습 데이터에 대해, 제안한 Cross-AVID와 CMA를 동시에 적용함으로써 최상의 결과를 얻을 수 있음을 보여줍니다.



