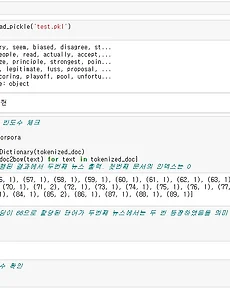
토픽 모델링3 [딥러닝을이용한 자연어 처리 입문] 0603 잠재 디리클레 할당(LDA) 실습2 ○ 실습 대상 데이터 - 약 15년 동안 발행되었던 뉴스 기사 제목을 모아놓은 영어 데이터(https://www.kaggle.com/therohk/million-headlines) ○ 텍스트 전처리 ○ TF-IDF 행렬 만들기 ○ 토픽 모델링 - 출처 : [딥러닝을이용한 자연어 처리 입문] 0603 잠재 디리클레 할당(LDA) 실습2 2021. 5. 17. [딥러닝을이용한 자연어 처리 입문] 0602 잠재 디리클레 할당 Latent Dirichlet Allocation, LDA 1. 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA) 개요 - 문서의 집합으로부터 어떤 토픽이 존재하는지를 알아내기 위한 알고리즘 - 단어의 순서는 신경쓰지 않음 - LDA 와 LSA의 차이 LSA : DTM을 차원 축소 하여 축소 차원에서 근접 단어들을 토픽으로 묶는다. LDA : 단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합확률로 추정하여 토픽을 추출한다. - 출처 : [딥러닝을이용한 자연어 처리 입문] 0602 잠재 디리클레 할당 Latent Dirichlet Allocation, LDA 2021. 5. 17. [딥러닝을이용한 자연어 처리 입문] 0601 잠재 의미 분석 Latent Semantic Analysis, LSA ○ 토픽(Topic) : 주제 ○ 토픽 모델링(Topic Modeling) - 문서 집합의 추상적인 주제를 발견하기 위한 통계적 모델 - 텍스트 본문의 숨겨진 의미 구조를 발견하기 위해 사용되는 텍스트 마이닝 기법 1. 잠재 의미 분석(Latent Semantic Analysis, LSA) - BoW에 기반한 DTM이나 TF-IDF의 단어의 의미를 고려하지 못하는 단점에 대한 대안으로 DTM의 잠재된 의미를 이끌어내는 방법으로 - 토픽 모델링을 위해 최적화 된 알고리즘은 아니지만, 토픽 모델링이라는 분야에 아이디어를 제공한 알고리즘 - SVD의 특성상 이미 계산된 LSA에 새로운 데이터를 추가하여 계산하려고하면 보통 처음부터 다시 계산해야 함. 즉 새로운 정보에 대해 업데이트가 어려움 - 출처 : [딥러.. 2021. 5. 17. 이전 1 다음