1. TF-IDF(단어 빈도-역 문서 빈도, Term Frequency-Inverse Document Frequency)
- 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법
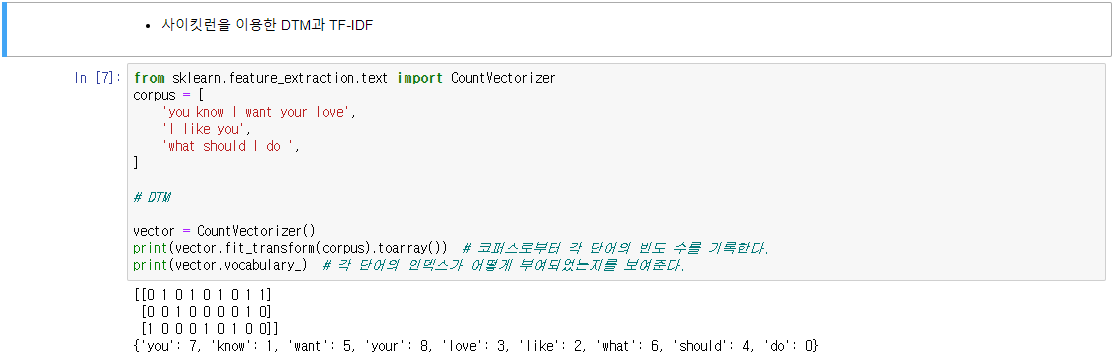
- 우선 DTM을 만든 후, TF-IDF 가중치를 부여
- 주로 문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내에서 특정 단어의 중요도를 구하는 작업 등에 쓰일 수 있음
- TF-IDF 식의 이해 (d: 문서, t: 단어, n: 문서의 총 개수)
- tf(d, t) : 특정 문서 d에서의 특정 단어 t의 등장 횟수
- df(t) : 특정 단어 t가 등장한 문서의 수
- idf(d, t) : log(n/1+df(t))
- 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단
- TF-IDF 값이 낮으면 중요도가 낮은 것이며, TF-IDF 값이 크면 중요도가 큰 것
2. 파이썬으로 TF-IDF 직접 구현하기





- 출처 : [딥러닝을이용한 자연어 처리 입문] 0404 TF-IDF (Term Frequency-Inverse Document Frequency)
'IT 와 Social 이야기 > NLP 자연어처리' 카테고리의 다른 글
| [딥러닝을이용한 자연어 처리 입문] 0502 여러가지 유사도 기법 (0) | 2021.05.17 |
|---|---|
| [딥러닝을이용한 자연어 처리 입문] 0501 코사인 유사도 Cosine Similarity (0) | 2021.05.17 |
| [딥러닝을이용한 자연어 처리 입문] 0402 Bag of Words(BoW) (0) | 2021.05.16 |
| [딥러닝을이용한 자연어 처리 입문] 0301 언어 모델 Language Model이란? (0) | 2021.05.16 |
| [딥러닝을이용한 자연어 처리 입문] 0210 한국어 전처리 패키지 Text Preprocessing Tools for Korean Text (0) | 2021.05.16 |



