
- 문서3은 문서2에서 단지 모든 단어의 빈도수가 1씩 증가했을 뿐인데 유사도의 값이 최대(1, 두 벡터의 방향이 완전히 동일)임
- 다시 말해 한 문서 내의 모든 단어의 빈도수가 동일하게 증가하는 경우에는 기존의 문서와 코사인 유사도의 값이 1이라는 것 (코사인 유사도는 문서의 길이가 다른 상황에서 비교적 공정한 비교를 할 수 있음)
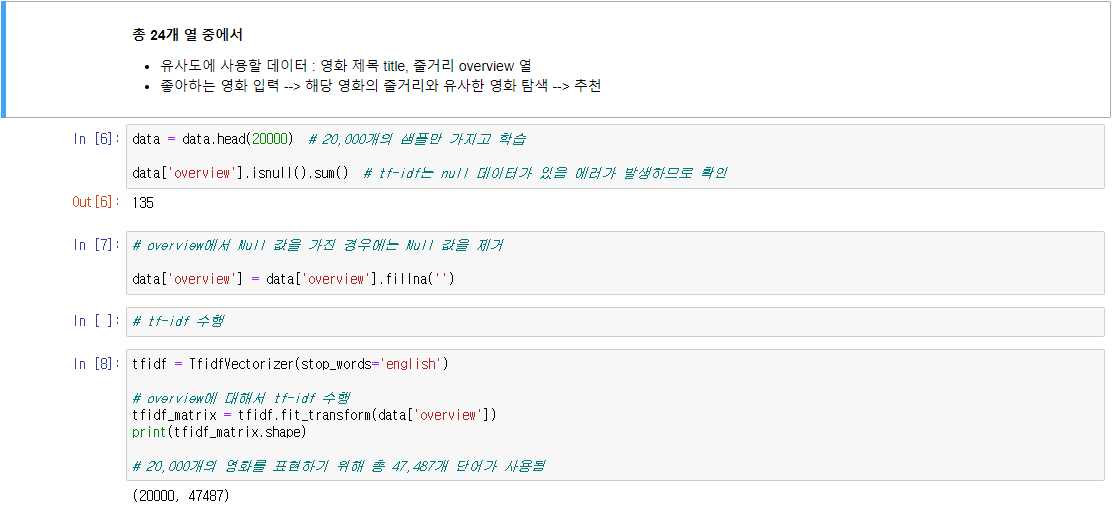
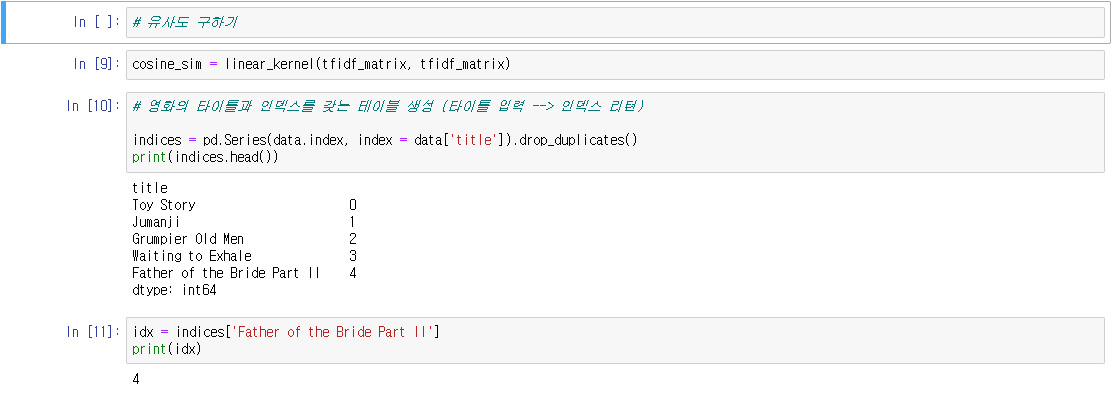
2. 유사도를 이용한 추천 시스템 구현하기
- TF-IDF와 코사인 유사도만으로 영화의 줄거리에 기반해서 영화를 추천


nlp_0501_cosine similarity 코사인 유사도.ipynb
0.01MB
'IT 와 Social 이야기 > NLP 자연어처리' 카테고리의 다른 글
| [딥러닝을이용한 자연어 처리 입문] 0601 잠재 의미 분석 Latent Semantic Analysis, LSA (0) | 2021.05.17 |
|---|---|
| [딥러닝을이용한 자연어 처리 입문] 0502 여러가지 유사도 기법 (0) | 2021.05.17 |
| [딥러닝을이용한 자연어 처리 입문] 0404 TF-IDF (Term Frequency-Inverse Document Frequency) (0) | 2021.05.17 |
| [딥러닝을이용한 자연어 처리 입문] 0402 Bag of Words(BoW) (0) | 2021.05.16 |
| [딥러닝을이용한 자연어 처리 입문] 0301 언어 모델 Language Model이란? (0) | 2021.05.16 |



