

1. 데이터의 양을 늘리기
- 데이터의 양을 늘릴 수록 모델은 데이터의 일반적인 패턴을 학습하여 과적합을 방지할 수 있음
- 의도적으로 기존의 데이터를 조금씩 변형하고 추가하여 데이터의 양을 늘리기도 함(데이터 증강 Data Augmentation)
2. 모델의 복잡도 줄이기
- 인공 신경망의 복잡도는 은닉층(hidden layer)의 수나 매개변수의 수 등으로 결정되므로 이 수를 조절함
3. 가중치 규제(Regularization) 적용하기
- L1 규제 : 가중치 w들의 절대값 합계를 비용 함수에 추가 (L1 노름)
- L2 규제 : 모든 가중치 w들의 제곱합을 비용 함수에 추가 (L2 노름)
4. 드롭아웃(Dropout)
- 학습 과정에서 신경망의 일부를 사용하지 않는 것
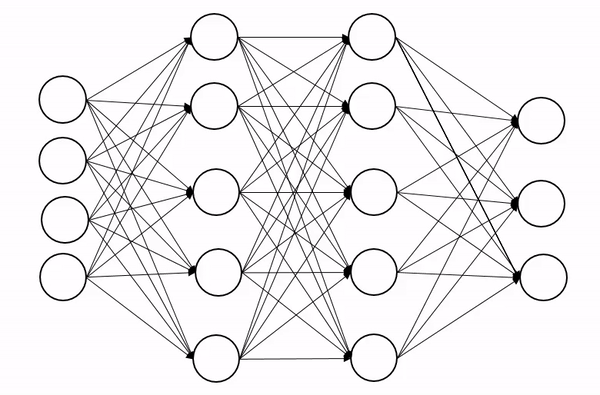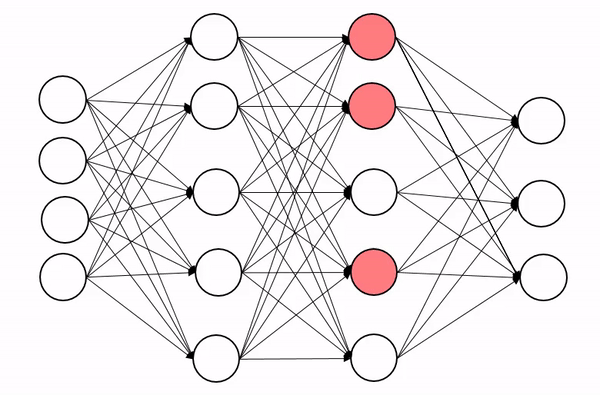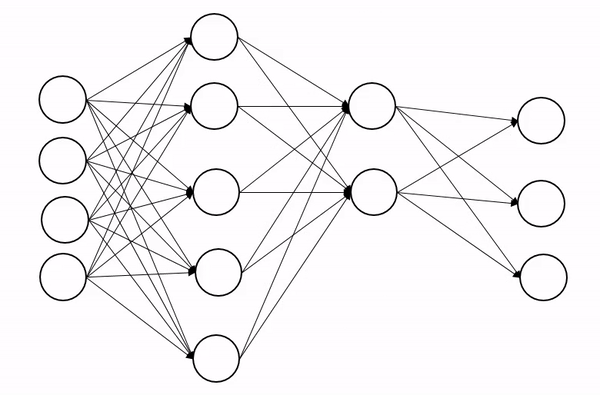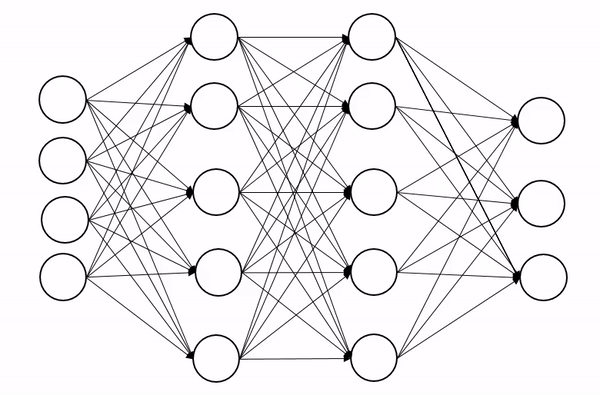
- 신경망 학습 시에만 사용하고, 예측 시에는 사용하지 않는 것이 일반적
- 매번 랜덤 선택으로 뉴런들을 사용하지 않으므로 서로 다른 신경망들을 앙상블하여 사용하는 것 같은 효과를 내어 과적합을 방지
'IT 와 Social 이야기 > NLP 자연어처리' 카테고리의 다른 글
| [딥러닝을이용한 자연어 처리 입문] 0806 케라스(Keras) 훑어보기 (0) | 2021.05.18 |
|---|---|
| [딥러닝을이용한 자연어 처리 입문] 0805 기울기 소실(Gradient Vanishing)과 폭주(Exploding)를 막는 방법 (0) | 2021.05.18 |
| [딥러닝을이용한 자연어 처리 입문] 0803 딥 러닝의 학습 방법 (0) | 2021.05.18 |
| [딥러닝을이용한 자연어 처리 입문] 0802 인공 신경망(Artificial Neural Network) 훑어보기 (0) | 2021.05.18 |
| [딥러닝을이용한 자연어 처리 입문] 0801 퍼셉트론(Perceptron) (0) | 2021.05.18 |



