- 나이브 베이즈 분류기에 입력 텍스트로 메일의 본문이 주어졌을 때, 입력 텍스트가 정상 메일인지 스팸 메일인지 구분하기 위한 확률을 아래와 같이 표현할 수 있음
P(정상 메일 | 입력 텍스트) = 입력 텍스트가 있을 때 정상 메일일 확률
P(스팸 메일 | 입력 텍스트) = 입력 텍스트가 있을 때 스팸 메일일 확률
- 이를 베이즈의 정리에 따라서 식을 표현하면
P(정상 메일 | 입력 텍스트) = (P(입력 텍스트 | 정상 메일) × P(정상 메일)) / P(입력 텍스트)
P(스팸 메일 | 입력 텍스트) = (P(입력 텍스트 | 스팸 메일) × P(스팸 메일)) / P(입력 텍스트)
- 식을 간소화하면
P(정상 메일 | 입력 텍스트) = P(입력 텍스트 | 정상 메일) × P(정상 메일)
P(스팸 메일 | 입력 텍스트) = P(입력 텍스트 | 스팸 메일) × P(스팸 메일)
- 나이브 베이즈 분류기에서는 각 단어에 대한 확률의 분모, 분자에 전부 숫자를 더해서 분자가 0이 되는 것을 방지하는 라플라스 스무딩을 사용하기도 함
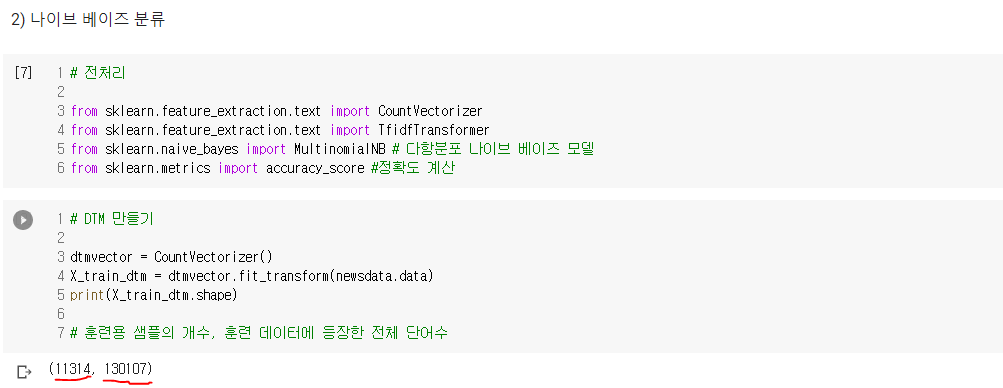
- 나이브 베이즈 분류를 위해서는 데이터를 BoW로 만들어줄 필요가 있음
3) 뉴스그룹 데이터 분류하기(Classification of 20 News Group with Naive Bayes Classifier)
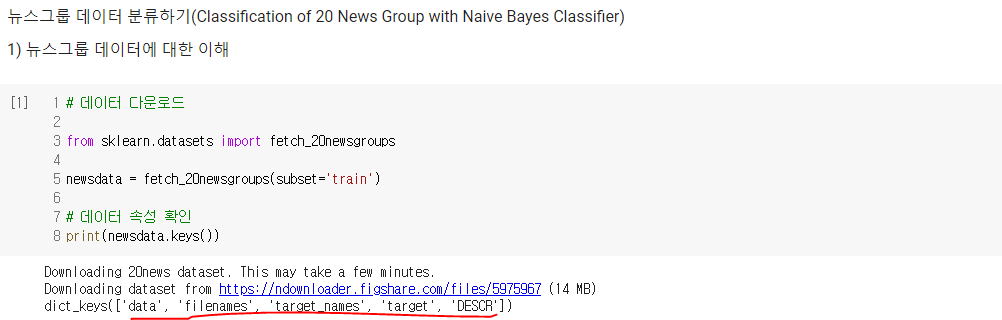
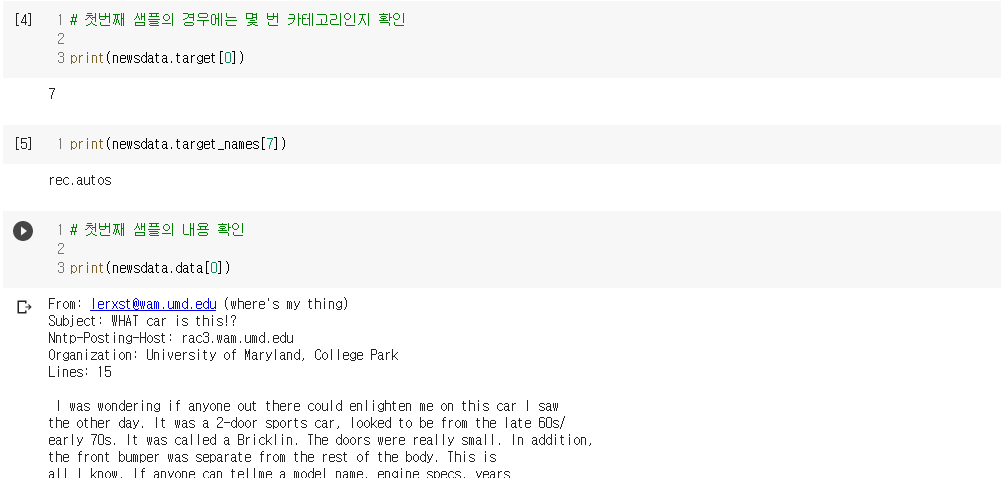
- 대상 데이터 : 20개의 다른 주제를 가진 18,846개의 뉴스그룹 데이터(훈련 데이터(11,314개)와 테스트 데이터(7,532개))
- 분류모델 : naive_bayes



- [딥러닝을이용한 자연어 처리 입문] 1105 나이브 베이즈 분류기(Naive Bayes Classifier)



