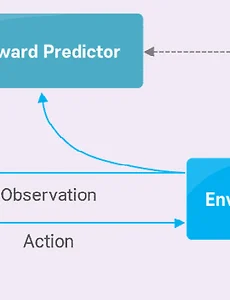
강화학습10 인간 피드백을 통한 강화학습(RLHF, Reinforcement Learning from Human Feedback) ● 강화학습(Reinforcement Learning) - 학습 데이터가 주어진 상태에서 변화가 없는 정적인 환경에서 진행되는 지도 학습이나 비지도 학습과 달리 불확실한 환경과 상호작용을 통해 주어진 업무를 학습 - 어떤 환경 안에서 정의된 주체(agent)가 현재의 상태를 관찰하며 선택할 수 있는 행동(action) 중 최대의 보상(reward)을 가져다주는 행동이 무엇인지 학습 ● 강화학습의 동작 순서 - 정의된 주체(agent)가 주어진 환경(environment)의 현재 상태(state)를 관찰(observation)하여, 행동 (action) 수행 → 환경의 상태가 변화하면서 정의된 주체에게 보상(reward) → 보상을 기반으로 정의된 주체는 더 많은 보상을 얻을 수 있는 방향(best act.. 2023. 4. 23. [ITFIND] 인공지능 전이학습(Transfer Learning)과 응용 분야 동향 [ Traditional ML vs. Transfer Learning ] [출처: [ITFIND 주간기술동향 "인공지능 전이학습과 응용 분야 동향 - 강수철 (주)롯데정보통신 정보기술연구소 수석연구원]] I. 서론 - 알파고를 만든 아버지로 불리는 데미스 하사비스(Demis Hassabis)는 알파고를 업그레이드시킨 알파고 제로(AlphaGo Zero)를 2017년에 내놓고 이에 대한 의학 분야 응용을 위해 적용한 전이학습(Transfer Learning) 기술에 대해 다음과 같이 언급하였다. “전이학습이 일반 인공지능으로 가는 열쇠가 될 것이라 생각합니다. 이를 위해서는 우선 학습한 사실에서 인지적인 세부사항을 추상화해야 합니다. 그리고 여기에서 개념적인 지식을 획득하는 것이 전이학습을 할 수 있는 핵.. 2020. 2. 23. [LGERI] 딥러닝 기반의 인공지능 자율주행 기술 경쟁의 핵심을 바꾼다 - 이승훈 *** 출처: [LGERI] 딥러닝 기반의 인공지능 자율주행 기술 경쟁의 핵심을 바꾼다 1. 딥러닝 기반의 자율주행 혁신의 시작 ■ 실리콘밸리의 Startup인 comma.ai - “사람이 운전하면 자동차가 주행하는 방법을 스스로 깨우친다”. - 실제 comma.ai는 지난 2016년 3월 이러한 방법으로 4주만에 자율 주행 학습이 가능한 인공지능을 만들어 자동차에 탑재했으며 10시간 동안의 학습으로 기본적인 자율주행 기능을 구현해 냈다. 고가의 특화 센서를 사용하지 않고 총 $1000 이하의 범용 센서만으로 딥러닝 기반 자율주행 기술을 개발하는 것을 목표로 하고 있다. - 단 4명의 개발 자가 4주만에 딥러닝을 활용해 구현해 낸 것이다. ■ 딥러닝을 적용해 기존 자율주행 개발 패러다임을 혁신한 것 - .. 2017. 11. 27. [김태훈] 강화 학습 기초 Reinforcement Learning an introduction 강화 학습 기초 Reinforcement Learning an introduction from Taehoon Kim 2017. 4. 14. 이전 1 2 3 다음