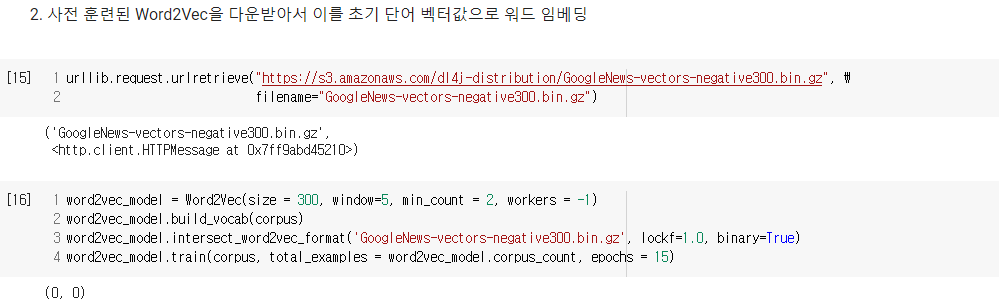
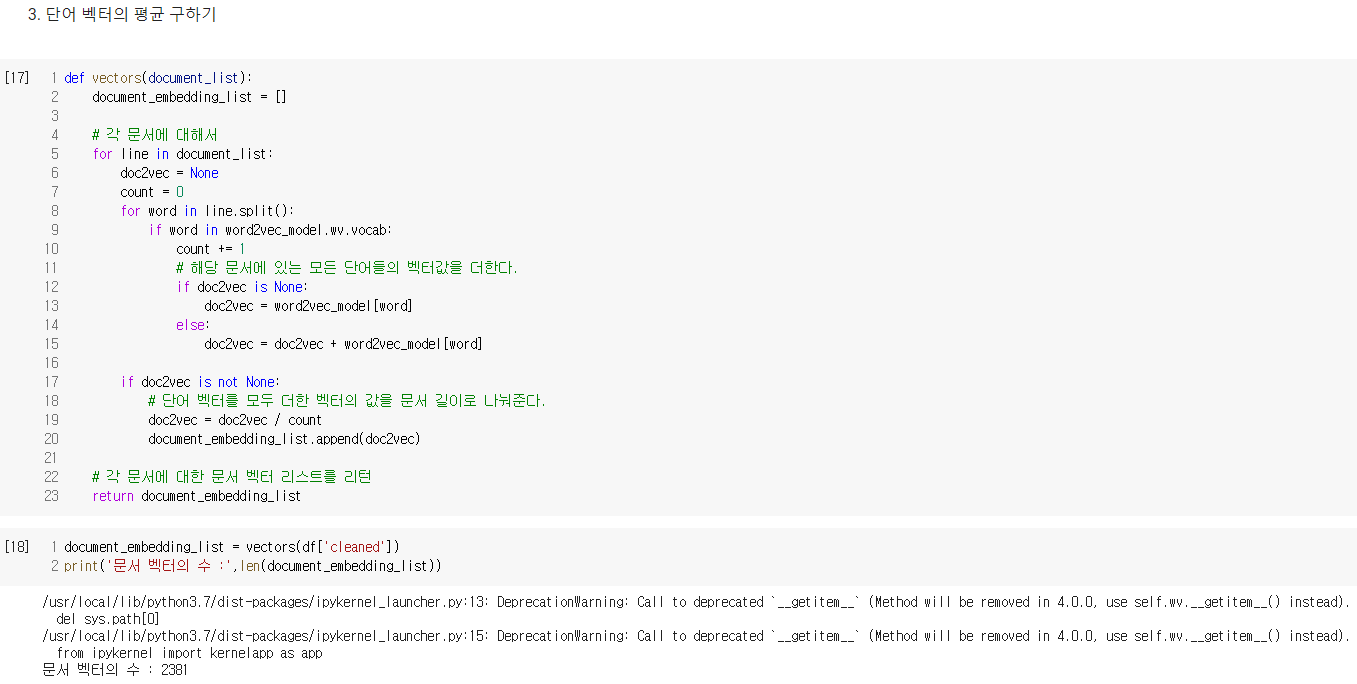
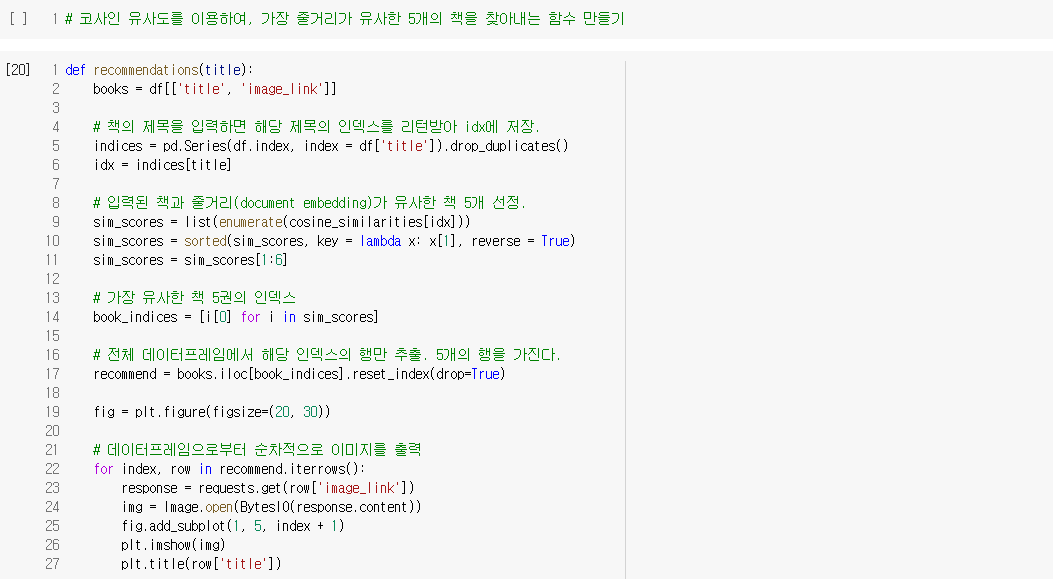
문서 내 각 단어들을 Word2Vec을 통해 단어 벡터로 변환하고, 이들의 평균으로 문서 벡터를 구하여 선호하는 도서와 유사한 도서를 찾아주는 도서 추천 시스템 만들기
- 데이터 다운로드 링크 : https://drive.google.com/file/d/15Q7DZ7xrJsI2Hji-WbkU9j1mwnODBd5A/view?usp=sharing
- 책의 이미지와(표지) 줄거리를 크롤링한 데이터

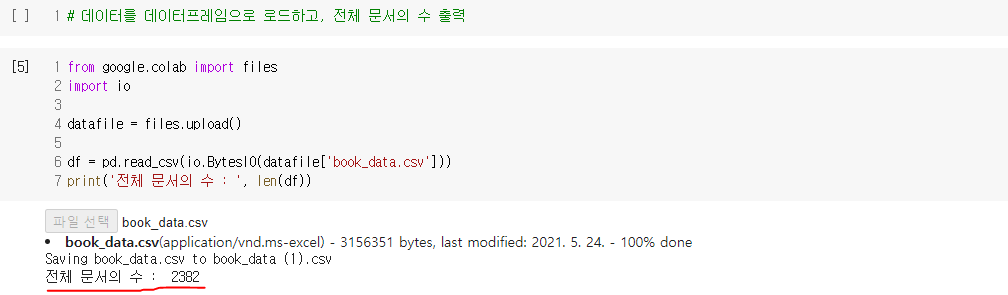
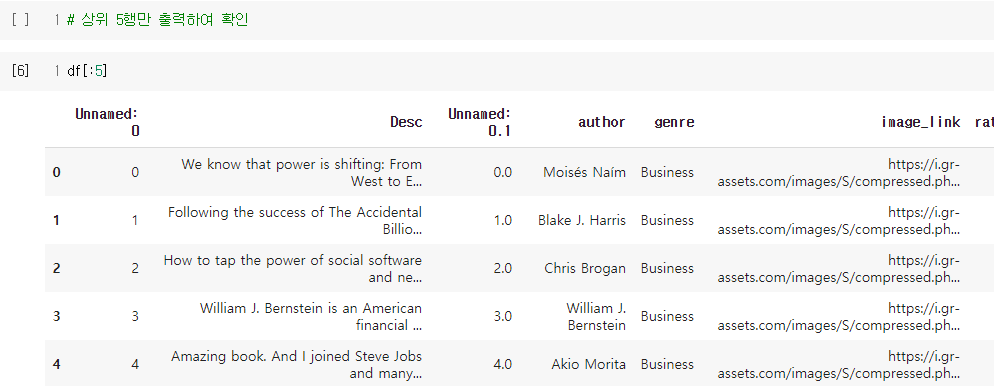
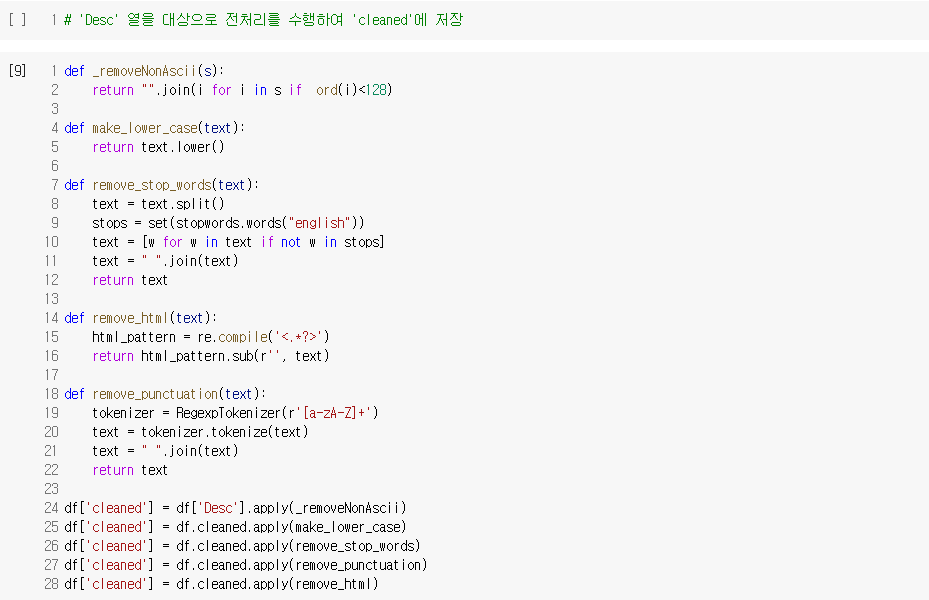
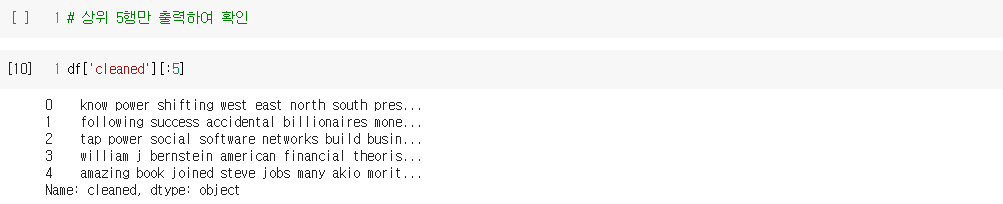




nlp_1011_recommendation_system_using_document_embedding_문서벡터를_이용한_추천.ipynb
0.01MB
- 출처 : [딥러닝을이용한 자연어 처리 입문] 1011 문서 벡터를 이용한 추천 시스템(Recommendation System using Document Embedding)
'IT 와 Social 이야기 > NLP 자연어처리' 카테고리의 다른 글
| [딥러닝을이용한 자연어 처리 입문] 1102 스팸 메일 분류하기(Spam Detection) (0) | 2021.05.24 |
|---|---|
| [딥러닝을이용한 자연어 처리 입문] 1012 워드 임베딩의 평균(Average Word Embedding) (0) | 2021.05.24 |
| [딥러닝을이용한 자연어 처리 입문] 1009 엘모(Embeddings from Language Model, ELMo) (0) | 2021.05.22 |
| [딥러닝을이용한 자연어 처리 입문] 1008 사전 훈련된 워드 임베딩(Pre-trained Word Embedding) (0) | 2021.05.22 |
| [딥러닝을이용한 자연어 처리 입문] 1006 패스트텍스트(FastText) (0) | 2021.05.21 |



