- 대상 데이터
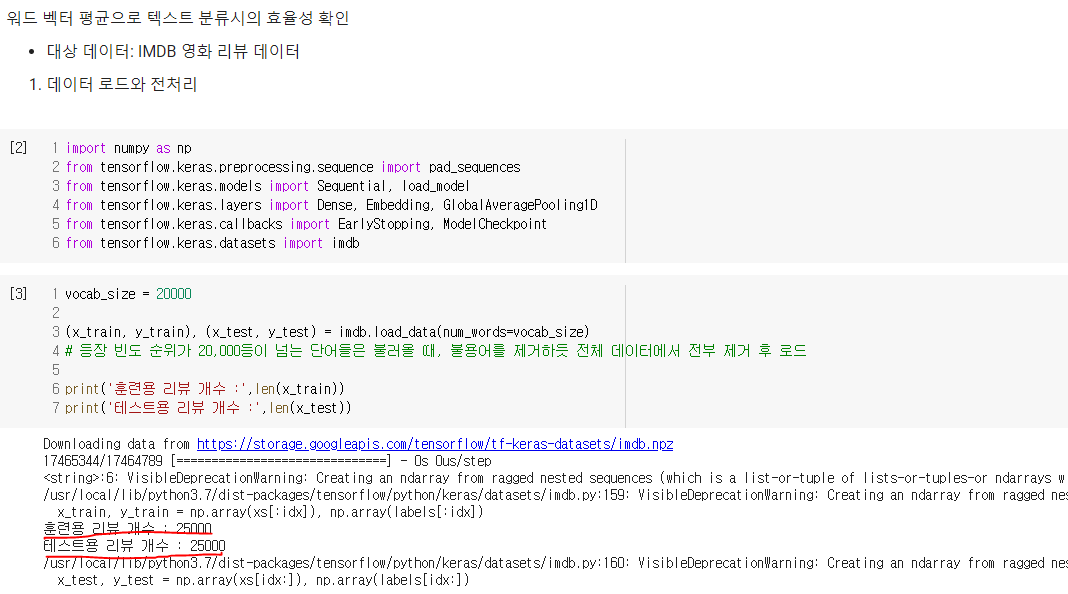
IMDB 영화 리뷰 데이터는 리뷰 텍스트에 리뷰가 긍정인 경우 1을, 부정인 경우 0으로 레이블링 한 데이터로 25,000개의 훈련 데이터와 테스트 데이터 25,000개로 구성된 데이터
- 단어 벡터들의 평균만으로 텍스트 분류를 수행시의 효율성 측정




nlp_1012_average_word_embedding_워드_임베딩의_평균.ipynb
0.01MB
- 출처 : [딥러닝을이용한 자연어 처리 입문] 1012 워드 임베딩의 평균(Average Word Embedding)



