


● 데이터 샘플링(sampling): 표본 선택
이미 있는 데이터 집합에서 일부를 무작위로 선택하는 것
numpy.random.choice(a, size=None, replace=True, p=None)
- a : 배열이면 원래의 데이터, 정수이면 arange(a) 명령으로 데이터 생성
- size : 정수. 샘플 숫자
- replace : 불리언. True이면 한번 선택한 데이터를 다시 선택 가능
- p : 배열. 각 데이터가 선택될 수 있는 확률
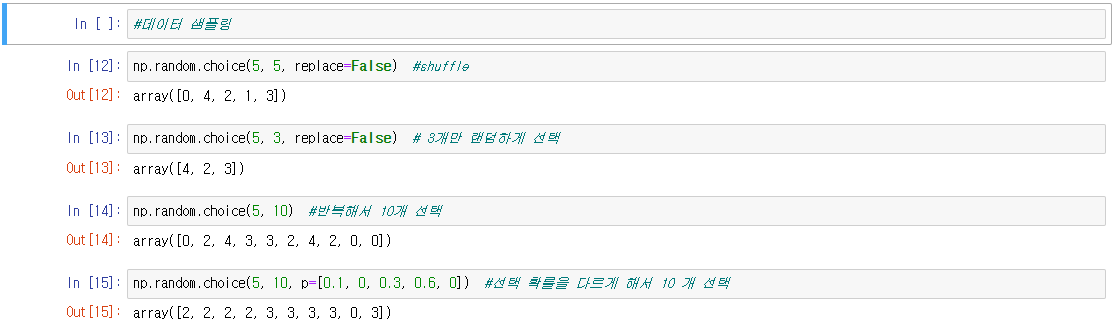


★★★
unique 함수는 데이터에 존재하는 값에 대해서만 갯수를 세므로 데이터 값이 나올 수 있음에도 불구하고 데이터가 하나도 없는 경우에는 정보를 주지 않는다. 예를 들어 주사위를 10번 던졌는데 6이 한 번도 나오지 않으면 이 값을 0으로 세어주지 않는다.
따라서 데이터가 주사위를 던졌을 때 나오는 수처럼 특정 범위안의 수인 경우에는 bincount 함수에 minlength 인수를 설정하여 쓰는 것이 더 편리하다. bincount 함수는 0 부터 minlength - 1 까지의 숫자에 대해 각각 카운트를 한다. 데이터가 없을 경우에는 카운트 값이 0이 된다.
★★★

dss3_5_random and counting.ipynb
0.01MB
'IT 와 Social 이야기 > Python' 카테고리의 다른 글
| [데이터 사이언스 스쿨] 4.2 판다스 데이터 입출력 (0) | 2021.04.27 |
|---|---|
| [데이터 사이언스 스쿨] 4.1 판다스 패키지 소개 (0) | 2021.04.27 |
| [데이터 사이언스 스쿨] 3.4 기술 통계 (0) | 2021.04.26 |
| [데이터 사이언스 스쿨] 3.3 배열의 연산 (0) | 2021.04.26 |
| [데이터 사이언스 스쿨] 3.2 배열의 생성과 변형 (0) | 2021.04.23 |



