- 토큰의 기준이 단어(word). 여기서 단어(word)는 단어 단위 외에도 단어구, 의미를 갖는 문자열로도 간주되기도 함
- 구두점이나 특수문자를 전부 제거하면 토큰이 의미를 잃어버리는 경우가 발생하기도 함
- 영어와 달리 한국어는 띄어쓰기만으로는 단어 토큰을 구분하기 어려움
2. 토큰화 중 생기는 선택의 순간
- 영어권 언어에서 아포스트로피를(')가 들어가있는 단어는 어떻게 토큰으로 분류해야할까



3. 토큰화에서 고려해야 할 사항
- 구두점이나 특수 문자를 단순 제외해서는 안 된다.
- 줄임말과 단어 내에 띄어쓰기가 있는 경우
- 표준 토큰화 예제(Penn Treebank Tokenization의 규칙)
- 하이푼으로 구성된 단어는 하나로 유지
- doesn't와 같이 아포스트로피로 '접어(clitic)'가 함께하는 단어는 분리

4. 문장 토큰화(Sentence Tokenization)
- 이 작업은 갖고있는 코퍼스 내에서 문장 단위로 구분하는 작업으로 때로는 문장 분류(sentence segmentation)라고도 함
- 어떻게 주어진 코퍼스로부터 문장 단위로 분류할 수 있을까?



5. 이진 분류기(Binary Classifier)
문장 토큰화에서의 예외 사항을 발생시키는 마침표의 처리를 위해서 입력에 따라 두 개의 클래스로 분류하는 이진 분류기(binary classifier)를 사용하기도 함
- 두 개의 클래스는
- 마침표(.)가 단어의 일부분일 경우. 즉, 마침표가 약어(abbreivation)로 쓰이는 경우
- 마침표(.)가 정말로 문장의 구분자(boundary)일 경우를 의미
- 어떤 마침표가 주로 약어(abbreviation)으로 쓰이는 지를 위한 약어 사전(abbreviation dictionary)이 쓰임
- 오픈 소스로는 NLTK, OpenNLP, 스탠포드 CoreNLP, splitta, LingPipe 등이 있음
6. 한국어 토큰화의 어려움
- 한국어는 교착어(조사, 어미 등을 부텨 말을 만드는 언어)이다.
- 대부분의 한국어 NLP에서 조사는 분리해줄 필요가 있음
- 한국어 토큰화에서는 형태소(morpheme; 뜻을 가진 가장 작은 말의 단위, 자립형태소, 의존형태소)란 개념을 반드시 이해해야 함
- 한국어는 띄어쓰기가 영어보다 잘 지켜지지 않는다.
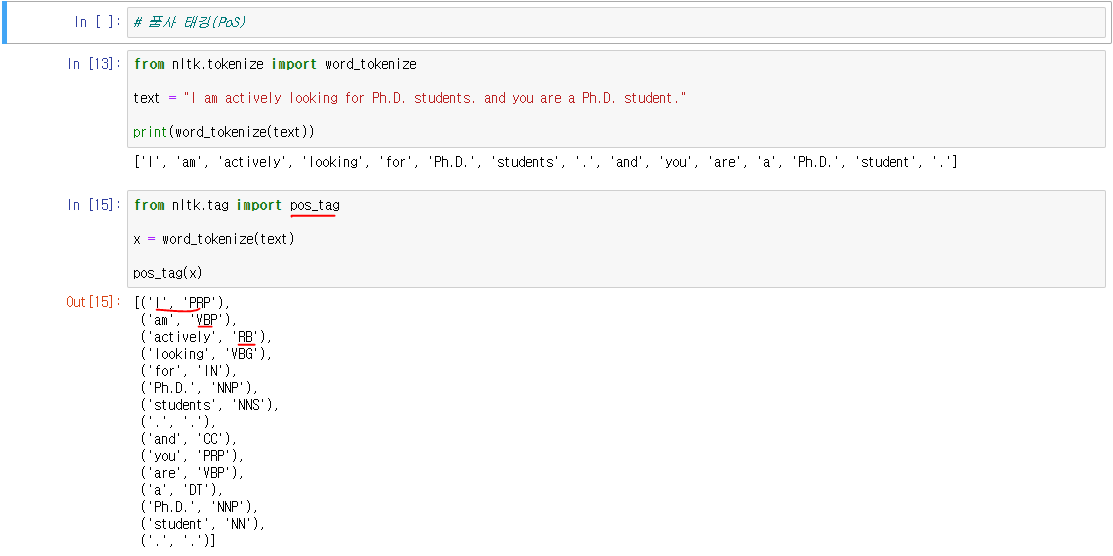
7. 품사 태깅(Part-of-speech tagging)
- 단어 토큰화 과정에서 각 단어가 어떤 품사로 쓰였는지를 구분해놓는 과정