
FastText는 하나의 단어 안에도 여러 단어들이 존재하는 것(각 단어를 글자 단위 n-gram의 구성으로 취급)으로 간주함. 즉 내부 단어(subword)를 고려하여 학습을 진행
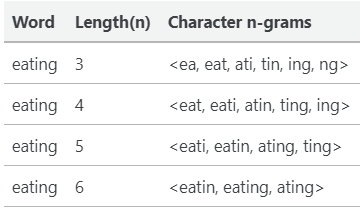
1. 내부 단어(subword)의 학습
- n-gram의 n을 3으로 잡은 경우
- apple
- <ap, app, ppl, ple, le>, <apple> : <(시작), >(끝), <apple>(특별 토큰)
- 내부 단어들을 벡터화한다는 의미는 저 단어들에 대해서 Word2Vec을 수행한다는 의미
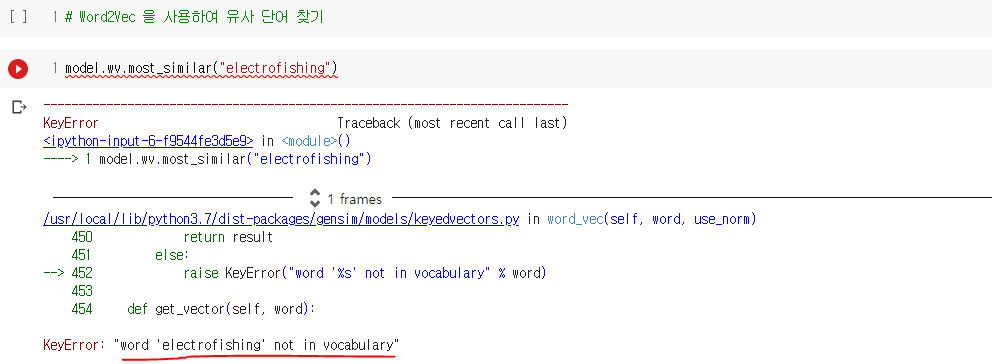
2. 모르는 단어(Out Of Vocabulary, OOV)에 대한 대응
- 학습 후 모든 데이터 셋의 모든 단어의 각 n-gram에 대해 워드 임베딩이 되므로 데이터 셋만 충분하다면 내부단어를 통해 OOV에 대해서도 다른 단어와의 유사도를 계산할 수 있음
3. 단어 집합 내 빈도 수가 적었던 단어(Rare Word)에 대한 대응
- 만약 단어가 희귀 단어라도, 그 단어의 n-gram이 다른 단어의 n-gram과 겹치는 경우라면, Word2Vec과 비교하여 비교적 높은 임베딩 벡터값을 얻음
- 노이즈, 오타 등의 희귀 단어에 대해서도 일정 수준의 성능을 보임
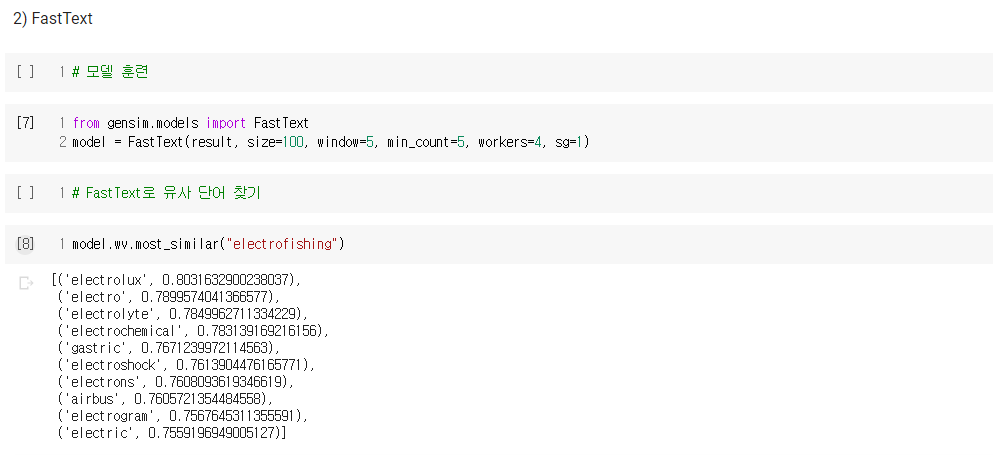
4. 실습으로 비교하는 Word2Vec Vs. FastText
nlp_1006_fasttext_패스트텍스트.ipynb
0.01MB
'IT 와 Social 이야기 > NLP 자연어처리' 카테고리의 다른 글
| [딥러닝을이용한 자연어 처리 입문] 1009 엘모(Embeddings from Language Model, ELMo) (0) | 2021.05.22 |
|---|---|
| [딥러닝을이용한 자연어 처리 입문] 1008 사전 훈련된 워드 임베딩(Pre-trained Word Embedding) (0) | 2021.05.22 |
| [딥러닝을이용한 자연어 처리 입문] 1005 글로브(GloVe) (0) | 2021.05.21 |
| [딥러닝을이용한 자연어 처리 입문] 1004 네거티브 샘플링을 이용한 Word2Vec 구현(Skip-Gram with Negative Sampling, SGNS) (0) | 2021.05.21 |
| [딥러닝을이용한 자연어 처리 입문] 1003 영어/한국어 Word2Vec 실습 (0) | 2021.05.21 |



