[1] 발표자 : DSBA 연구실 석사과정 정의석
[2] 발표 논문 : https://arxiv.org/abs/2103.10697
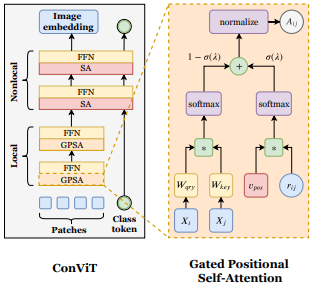
ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
Convolutional architectures have proven extremely successful for vision tasks. Their hard inductive biases enable sample-efficient learning, but come at the cost of a potentially lower performance ceiling. Vision Transformers (ViTs) rely on more flexible s
arxiv.org



