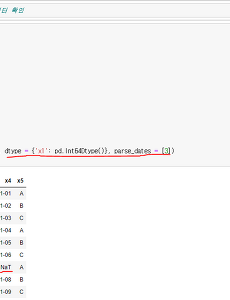
IT 와 Social 이야기/Python348 [데이터 사이언스 스쿨] ml2.1 데이터 전처리 기초 ○ missingno 패키지 : pandas 데이터프레임에서 결측(missing) 데이터를 찾는 기능을 제공 - 데이터프레임에 결측 데이터가 NaN(not a number) 값으로 저장되어 있어야 한다. - 주의할 점은 NaN값은 부동소수점 실수 자료형에만 있는 값이므로 정수 자료를 데이터프레임에 넣을 때는 Int64Dtype 자료형을 명시해주어야 하고 시간 자료형을 넣을 때도 parse_dates 인수로 날짜시간형 파싱을 해주어야 datetime64[ns] 자료형이 되어 결측 데이터가 NaT(not a time) 값으로 표시된다. ○ 결측 데이터 처리 결측된 데이터가 너무 많은 경우 해당 데이터 열 전체를 삭제할 수 있다. 결측된 데이터가 일부인 경우 가장 그럴듯한 값으로 대체할 수 있다. 이를 결측 .. 2021. 5. 6. [데이터 사이언스 스쿨] ml1.1 데이터 분석의 소개 ● 예측(prediction) : 예측이란 숫자, 문서, 이미지, 음성, 영상 등의 여러 가지 입력 데이터를 주면, 데이터 분석의 결과로 다른 데이터를 출력하는 분석 방법이다. - 데이터 분석에서 말하는 예측이라는 용어는 시간상으로 미래의 의미는 포함하지 않는다. 시계열 분석에서는 시간상으로 미래의 데이터를 예측하는 경우가 있는데 이 때는 미래예측(forecasting) 이라는 용어를 사용한다. ● 입력 데이터(input data) : 분석의 기반이 되는 데이터로 보통 알파벳 X로 표기한다. - 독립변수(independent variable), 특징(feature), 설명변수(explanatory variable) 등의 용어로 쓰기도 한다. ● 출력 데이터(output data) : 추정하거나 예측하고자.. 2021. 5. 5. [데이터 사이언스 스쿨] math 10.4 상호정보량 ● 상호정보량(mutual information) : 결합확률밀도함수 p(x,y)와 주변확률밀도함수의 곱 p(x)p(y)의 쿨벡-라이블러 발산이다. 즉 결합확률밀도함수와 주변확률밀도함수의 차이를 측정하므로써 두 확률변수의 상관관계를 측정하는 방법이다. 만약 두 확률변수가 독립이면 결합확률밀도함수는 주변확률밀도함수의 곱과 같으므로 상호정보량은 0이 된다. 반대로 상관관계가 있다면 그만큼 양의 상호정보량을 가진다. ● 최대정보상관계수(maximal information coefficient, MIC) : 구간을 나누는 방법을 다양하게 시도한 다음에 그 결과로 구한 다양한 상호정보량 중에서 가장 큰 값을 선택하여 정규화한 것 - 출처 : [데이터 사이언스 스쿨] math 10.4 상호정보량 2021. 5. 5. [데이터 사이언스 스쿨] math 10.3 교차엔트로피와 쿨백-라이블러 발산 ● 교차엔트로피(cross entropy) : 분류문제의 성능을 평가하는데 유용 ● 쿨백-라이블러 발산(Kullback-Leibler divergence) : 교차엔트로피를 응용한 것으로 두 확률분포의 모양이 얼마나 유사한지를 평가 - 출처 : [데이터 사이언스 스쿨] math 10.3 교차엔트로피와 쿨백-라이블러 발산 2021. 5. 5. 이전 1 ··· 17 18 19 20 21 22 23 ··· 87 다음